Object Detection
Description
The object detection tool is a powerful feature that enables the user to identify and locate various objects within images. It utilises a pre-trained model, which has been trained on a vast amount of data to localise and classify different objects.
By applying this tool to an image, the user can automatically localise and identify objects present in the image. The object detection tool offers a convenient and efficient way to perform object recognition tasks without the need for manual intervention or extensive personnel training.
Settings
Model Folder Path
The model folder path is the path to the folder containing the model files. The model files are the files that are used to detect objects in the images. The model folder path can be a local path or a remote path.
See Model Folder Structure for more information about how to structure the model folder.
Supported Architectures
Here are the supported frameworks and architectures:
TensorFlow 1
TensorFlow 1 architectures
| Architecture | Backbone | Input Size | Model File Type |
|---|---|---|---|
| Faster R-CNN | Inception V2 | 1000x1000 | .pb & .pbtxt |
| Faster R-CNN | ResNet50 | 1000x1000 | .pb & .pbtxt |
| SSD | Inception V2 | 300x300 | .pb & .pbtxt |
| SSD | MobileNet V2 | 300x300 | .pb & .pbtxt |
| SSDLite | MobileNet V2 | 300x300 | .pb & .pbtxt |
DarkNet
DarkNet architectures
| Architecture | Backbone | Input Size | Model File Type |
|---|---|---|---|
| YOLO Tiny V3 | DarkNet | 416x416 | .weights & .cfg |
| YOLO V3 | DarkNet | 416x416 | .weights & .cfg |
| YOLO V4 | CSPDarkNet | 416x416 | .weights & .cfg |
TensorFlow 2 - ONNX
TensorFlow 2 architectures
| Architecture | Backbone | Input Size | Model File Type |
|---|---|---|---|
| CenterNet | Hourglass104 | 512x512 | .onnx |
| CenterNet | Hourglass104 | 1024x1024 | .onnx |
| EfficientDet-D0 | EfficientNet-B0 | 512x512 | .onnx |
| EfficientDet-D1 | EfficientNet-B1 | 640x640 | .onnx |
| EfficientDet-D2 | EfficientNet-B2 | 768x768 | .onnx |
| EfficientDet-D3 | EfficientNet-B3 | 896x896 | .onnx |
| EfficientDet-D4 | EfficientNet-B4 | 1024x1024 | .onnx |
| EfficientDet-D5 | EfficientNet-B5 | 1280x1280 | .onnx |
| EfficientDet-D6 | EfficientNet-B6 | 1280x1280 | .onnx |
| EfficientDet-D7 | EfficientNet-B7 | 1536x1536 | .onnx |
| SSD | MobileNet V2 | 320x320 | .onnx |
| SSD | MobileNet V2 | 640x640 | .onnx |
| SSD | MobileNet V2 | 1024x1024 | .onnx |
| Faster R-CNN | ResNet50 | 640x640 | .onnx |
| Faster R-CNN | ResNet50 | 1024x1024 | .onnx |
| Faster R-CNN | ResNet50 | 1333x800 | .onnx |
MMYolo
MMYolo architectures
| Architecture | Backbone | Input Size | Model File Type |
|---|---|---|---|
| YOLOv5-n | CSPDarkNet (P5) | 640x640 | .onnx |
| YOLOv5-s | CSPDarkNet (P5) | 640x640 | .onnx |
| YOLOv5-m | CSPDarkNet (P5) | 640x640 | .onnx |
| YOLOv5-l | CSPDarkNet (P5) | 640x640 | .onnx |
| YOLOv5-x | CSPDarkNet (P5) | 640x640 | .onnx |
| YOLOv5-n | CSPDarkNet (P6) | 1280x1280 | .onnx |
| YOLOv5-s | CSPDarkNet (P6) | 1280x1280 | .onnx |
| YOLOv5-m | CSPDarkNet (P6) | 1280x1280 | .onnx |
| YOLOv5-l | CSPDarkNet (P6) | 1280x1280 | .onnx |
| YOLOv6-n | EfficientRep (P5) | 640x640 | .onnx |
| YOLOv6-t | EfficientRep (P5) | 640x640 | .onnx |
| YOLOv6-s | EfficientRep (P5) | 640x640 | .onnx |
| YOLOv6-m | EfficientRep (P5) | 640x640 | .onnx |
| YOLOv6-l | EfficientRep (P5) | 640x640 | .onnx |
| YOLOv7-tiny | CSPDarknet53 (P5) | 640x640 | .onnx |
| YOLOv7-l | CSPDarknet53 (P5) | 640x640 | .onnx |
| YOLOv7-x | CSPDarknet53 (P5) | 640x640 | .onnx |
| YOLOv7-w | CSPDarknet53 (P6) | 1280x1280 | .onnx |
| YOLOv7-d | CSPDarknet53 (P6) | 1280x1280 | .onnx |
| YOLOv8-n | CSPDarknet53+PANet (P5) | 640x640 | .onnx |
| YOLOv8-s | CSPDarknet53+PANet (P5) | 640x640 | .onnx |
| YOLOv8-m | CSPDarknet53+PANet (P5) | 640x640 | .onnx |
| YOLOv8-l | CSPDarknet53+PANet (P5) | 640x640 | .onnx |
| YOLOv8-x | CSPDarknet53+PANet (P5) | 640x640 | .onnx |
| YOLOX-t | Swin Transformer | 640x640 | .onnx |
| YOLOX-s | Swin Transformer | 640x640 | .onnx |
| YOLOX-m | Swin Transformer | 640x640 | .onnx |
| YOLOX-l | Swin Transformer | 640x640 | .onnx |
| YOLOX-x | Swin Transformer | 640x640 | .onnx |
| PPYOLOE+-s | PVTv2 | 640x640 | .onnx |
| PPYOLOE+-m | PVTv2 | 640x640 | .onnx |
| PPYOLOE+-l | PVTv2 | 640x640 | .onnx |
| PPYOLOE+-x | PVTv2 | 640x640 | .onnx |
| RTMDet-tiny | ResNet-FPN | 640x640 | .onnx |
| RTMDet-s | ResNet-FPN | 640x640 | .onnx |
| RTMDet-m | ResNet-FPN | 640x640 | .onnx |
| RTMDet-l | ResNet-FPN | 640x640 | .onnx |
| RTMDet-x | ResNet-FPN | 640x640 | .onnx |
MMDetection
MMDetection architectures
| Architecture | Backbone | Input Size | Model File Type |
|---|---|---|---|
| RTMDet-tiny | ResNet-FPN | 640x640 | .onnx |
| RTMDet-s | ResNet-FPN | 640x640 | .onnx |
| RTMDet-m | ResNet-FPN | 640x640 | .onnx |
| RTMDet-l | ResNet-FPN | 640x640 | .onnx |
| RTMDet-x | ResNet-FPN | 640x640 | .onnx |
| YOLOX-t | Swin Transformer | 640x640 | .onnx |
| YOLOX-s | Swin Transformer | 640x640 | .onnx |
| YOLOX-m | Swin Transformer | 640x640 | .onnx |
| YOLOX-l | Swin Transformer | 640x640 | .onnx |
| YOLOX-x | Swin Transformer | 640x640 | .onnx |
| CenterNet | ResNet-18 | 1024x1024 | .onnx |
| CenterNet | ResNet-50 | 1024x1024 | .onnx |
| CenterNet | ResNet-101 | 1024x1024 | .onnx |
| CenterNet | ResNet-50 | 1088x800 | .onnx |
| Faster R-CNN | R-50-C4 (Caffe) | 1088x800 | .onnx |
| Faster R-CNN | R-50-DC5 (Caffe) | 1088x800 | .onnx |
| Faster R-CNN | R-50-FPN (Caffe) | 1088x800 | .onnx |
| Faster R-CNN | R-50-FPN (PyTorch) | 1088x800 | .onnx |
| Faster R-CNN | R-101-FPN (Caffe) | 1088x800 | .onnx |
| Faster R-CNN | R-101-FPN (PyTorch) | 1088x800 | .onnx |
| Faster R-CNN | X-101-32x4d-FPN (PyTorch) | 1088x800 | .onnx |
| Faster R-CNN | X-101-64x4d-FPN (PyTorch) | 1088x800 | .onnx |
| Swin (Mask R-CNN) | Swin-T | 1088x800 | .onnx |
| Cascade R-CNN | R-50-FPN (Caffe) | 1088x800 | .onnx |
| Cascade R-CNN | R-50-FPN (PyTorch) | 1088x800 | .onnx |
| Cascade R-CNN | R-101-FPN (Caffe) | 1088x800 | .onnx |
| Cascade R-CNN | R-101-FPN (PyTorch) | 1088x800 | .onnx |
| Cascade R-CNN | X-101-32x4d-FPN (PyTorch) | 1088x800 | .onnx |
| Cascade R-CNN | X-101-64x4d-FPN (PyTorch) | 1088x800 | .onnx |
Others
Others architectures
| Architecture | Backbone | Input Size | Model File Type | link |
|---|---|---|---|---|
| YOLO-World | DarkNet | 640x640 | .onnx | link |
Zene UI

The user can choose the model folder path by clicking on the folder icon and selecting the folder containing the model files (see File Explorer for more information).
In this example, the model folder is located at D:/ontf2_faster_rcnn_resnet50_v1_640x640. Below the model path selector the user can see the Model Name (folder name), and the model Framework.
Architecture
The architecture is the type of model that will be used to detect objects in the images. See Supported Architecture for more information.
NMS Threshold
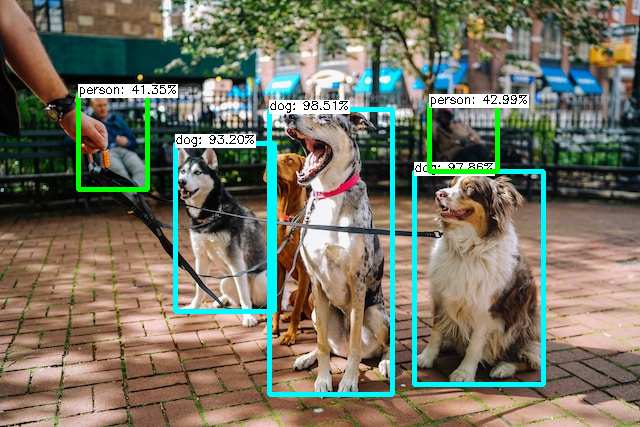
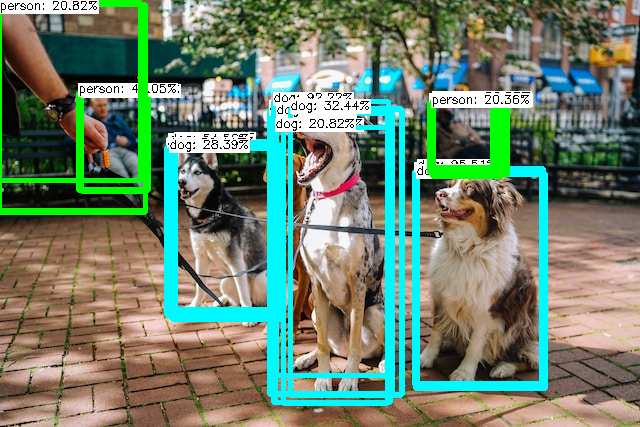
The NMS threshold is the minimum threshold for non-maximum suppression. Non-maximum suppression is a technique used to reduce the number of bounding boxes by removing the ones that overlap too much with other bounding boxes. A lower NMS threshold will result in fewer bounding boxes, but with potentially higher accuracy, whereas a higher threshold will result in more bounding boxes, but with lower accuracy.
Confidence Threshold
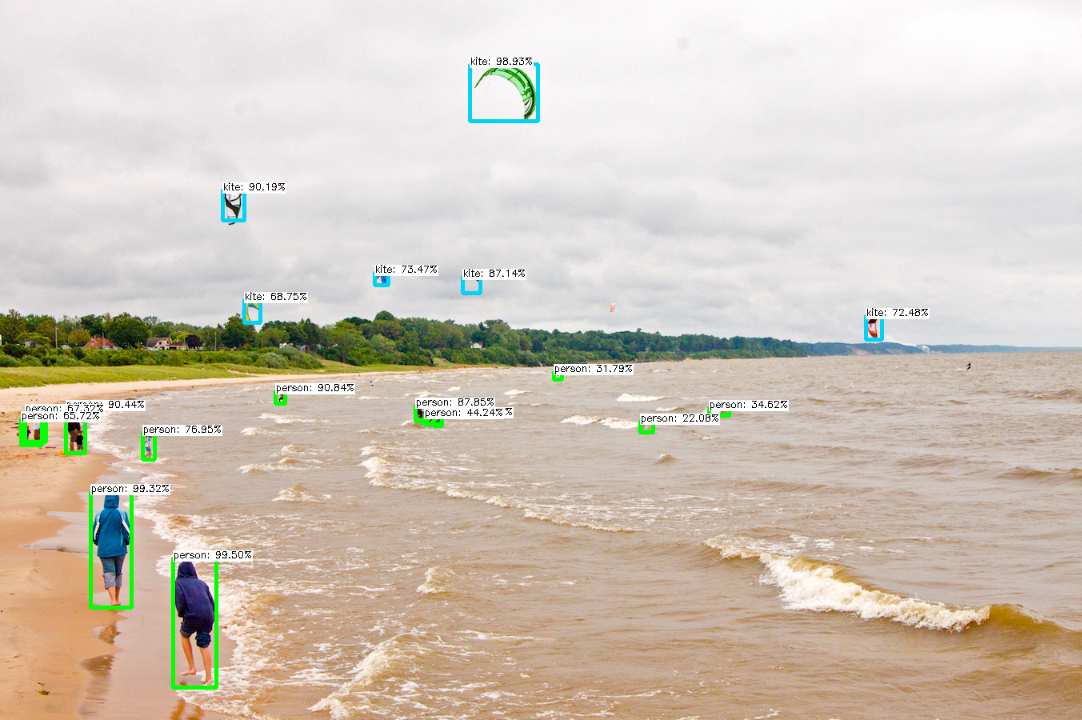

The confidence threshold is the minimum confidence score a detection should have to be considered valid. Detections with confidence scores below this threshold will be discarded. A higher confidence threshold will result in fewer detections, but with higher accuracy, whereas a lower threshold will result in more detections, but with potentially lower accuracy.
Split Frame
Whether to split the frame into multiple frames before detecting objects. This is useful when the image is too large to be processed by the model.
Transform Contains
A list of configurations for transforming a detected primary object into another object based on whether they are other objects within the primary object. For example, if the user wants to transform the detected person object into a group object when there are multiple person objects within the primary person object, the user can add a configuration to the transform contains list.
See Detected Object Transformation Contain for more information.
Transform Labels
A list of class labels' original names and their transformed names. All the labels are inherited from after transforming contained objects.
Keep Labels
The keep labels are the labels that will be kept when detecting objects. For example, if the user want to keep only the person label, the user can add only person to the keep labels list.
Ignore Labels
The ignored labels are the labels that will be ignored when detecting objects. For example, if the user want to ignore the person label, the user can add person to the ignored labels list.
Advanced Settings
Whether to enabled advanced settings. The advanced settings allow the user to have more control over the model parameters.
Please use the advanced settings with caution as changing the parameters could result in unexpected behaviour.
To RGB
Advanced SettingsConvert from BGR colours (default in Zene) to RGB colours.This is useful when using models trained on images with different channel orders.
Scale
Advanced SettingsThe scale is the scale factor that is applied to the input image. The scale factor is used to normalise the input image before it is passed to the model. The scale factor is calculated by dividing the input image by the scale factor. A higher scale factor will result in a smaller input image, while a lower scale factor will result in a larger input image.
Mean
Advanced SettingsThe mean is the mean value that is subtracted from the input image. The mean value is used to normalise the input image before it is passed to the model. The mean value is calculated by subtracting the input image by the mean value. A higher mean value will result in a darker input image, while a lower mean value will result in a brighter input image.
Input Pixel (width and height)
Advanced SettingsThe input pixel is the size of the input image. The input image is the image that is passed to the model. The user can specify the width and height of the input image.
Display Results
Overlay Results
Whether to draw the results on top of the image frame.